



In this blog post, big data hadoop architect will explain the technology Oozie, how it is executed and during execution, what errors happen. Read this post and understand what they are trying to explain.
When we talk about Hadoop job scheduling or Hadoop workflow management in Big Data, then the first name which comes in everyone’s mouth is Apache Oozie.
When you try to use Big Data in its raw form then it rarely satisfies the requirements for performing data processing tasks. There are multiple actions by different ecosystems under Big Data environment which needs to be attach together.

Technology:
Oozie is a framework that helps automating multiple actions and codify this work into repeatable units or workflows that can be reused over time without the need to write any new code or steps.
Although Oozie meets most of the requirements for Hadoop job scheduling and it’s easy to understand and execute but there are still few necessities which needs to be meet to implement the whole process in place and without that we will be getting errors, we will discuss few error in detail here.
Description:
We will take an example of Hive script which is scheduled with the help of Oozie.
Below is the Workflow.xml file in which we have declared hive script location and parametrized jobTracker and nameNode location.
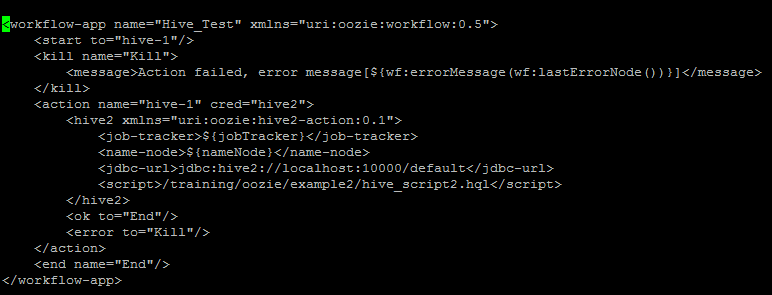
One can see the hive script below in which we are creating a database and then creating a table under it.

Job.properties file contains the value of nameNode and jobTracker.
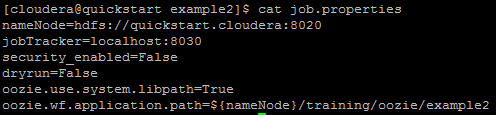
Issue -1:
Most of the time user who submit the fileget confused between the address and port number of the resource manager which we need to put while creating job.properties file and then come up with the error “JA002: SIMPLE authentication is not enabled” or “Connection refused” error.
Please refer to below screen shot for the same.
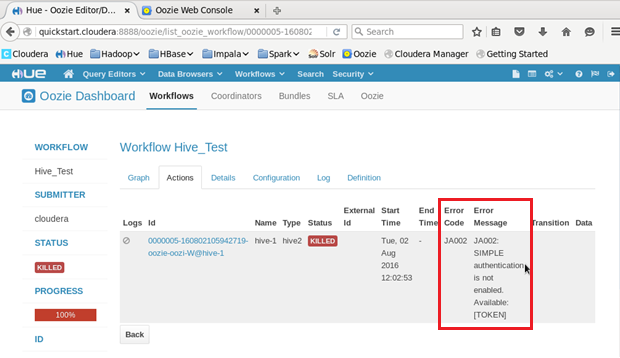
Error Description:
Port number of the resource manager does not match with the port number mentioned in job.properties file.
Resolution:
Please refer to “yarn.resourcemanager.address” property under YARN-DEFAULT.xml file for the actual resource manager, there are multiple entries of the address and port number under it but all Hadoop applications are looking for the port number mentioned in “yarn.resourcemanager.address” property.
Below is the screen shot for the same.

Issue -2:
When we submit the job in Oozie, in the backend of it always creates a share/lib in HDFS.
Path -> /user/oozie/share/lib/
Under this path oozie automatically copy all the necessary jars for all the ecosystems it is been using, for an example if you want to submit and Hive script with Oozie, then in HDFS there must be hive jars which will be placed under /user/oozie/share/lib/lib_20160406012735/hive.
Accordingly when you sqoop job which is trying to pull a data from mysql database and ingest into HDFS, then all the necessary jars will be automatically copied under/user/oozie/share/lib/lib_20160406012735/sqoop.
Here comes the twist, Oozie should be having mysql-connection jar under the above mentioned path but it will not copy mysql-connector jar automatically and due to the absence of it, we will get following error.
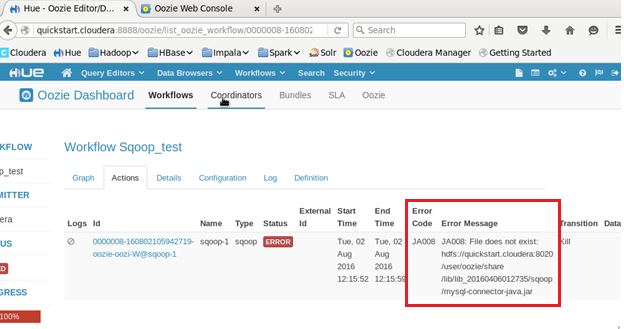
Error Description:
Mysql connector jar is not present in the share/lib folder of oozie-sqoop, due to which it won’t be able to recognize the mysql commands.
Resolution:
We have manually insert external sources jar file under share/lib folder of oozie-sqoop, in the above scenario it is mysql.
Conclusion:
Oozie does schedule your jobs on the timely manner but it does not always automate all the stuff, we need to extra careful while submitting the job and all the actions need to take care before submitting it.
Hope Big Data Hadoop Architect have made you clear about the technology Oozie. You can try yourself and execute it and fix errors like pro.
Ethan Millar
Latest posts by Ethan Millar (see all)
- The Future Of Machine Learning And Data Science - September 26, 2017
- Easy Way to Add Help Section in CRM Entity Form - July 28, 2017
- Customized Deployment for Spring Boot Applications - June 2, 2017